
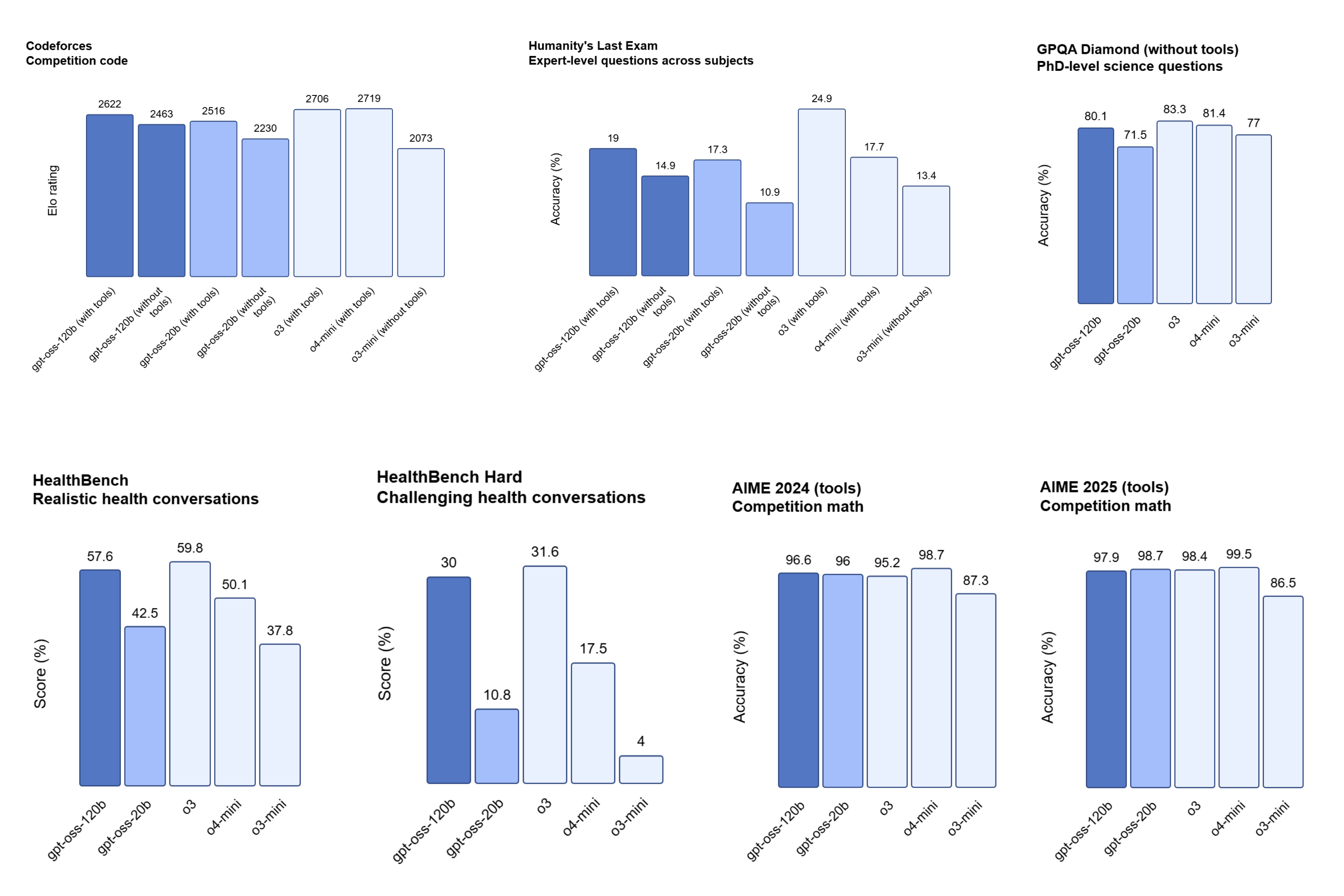
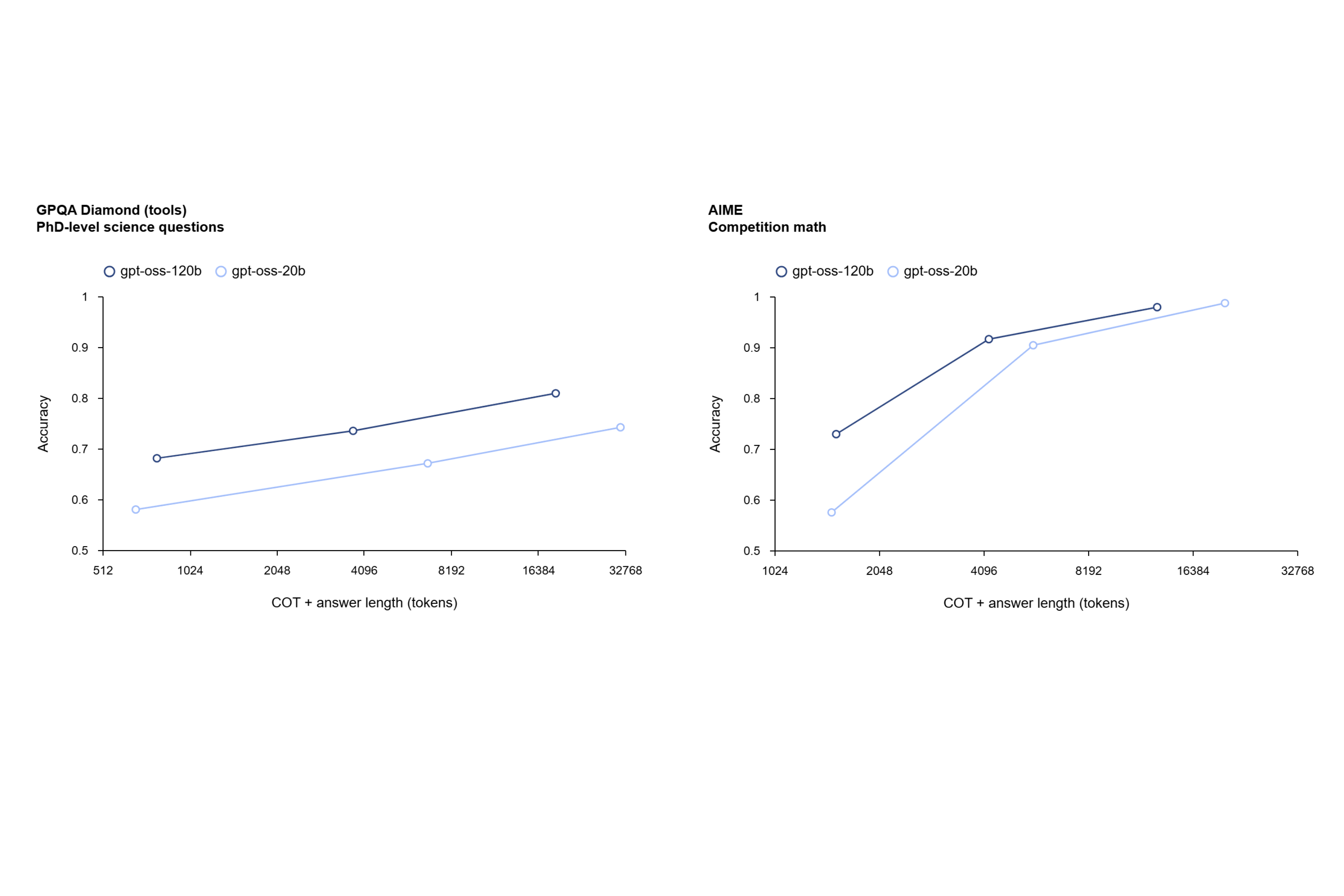
Descargar los pesos de gpt-oss desde Hugging Face
Ve a Hugging Face para descargar gpt-oss fácilmente. Busca "openai/gpt-oss-20b" o "openai/gpt-oss-120b" en huggingface.co. Usa la CLI de Hugging Face: ejecuta huggingface-cli download openai/gpt-oss-20b en tu terminal. Los modelos vienen cuantizados para mayor eficiencia, y puedes iniciar un servidor con vLLM para pruebas. Esta plataforma comunitaria también ofrece guías para ajuste fino con Transformers.